由于模拟登陆的需要,需要做验证码识别
基本原理
简单验证码识别主要原理还是 建立模型 > 去噪点 > 二值化 > 对比 如果是复杂一点的验证码则另论 下面简单介绍简单验证码的识别
大致思路
- 先打开原始图片

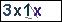

import Image
im = Image.open("temp.jpg")
- 图片灰度处理
im = im.convert('L')
灰度处理后的效果
![]()
![]()
![]()
- 根据阀值(threshold)生成表 table 再根据 table 对图片二值化处理
threshold = 140
table = [0 if i < threshold else 1 for i in range(256)]
im = im.point(table, '1')
二值化处理后的效果
![]()
![]()
![]()
- 将二值化后的图片转为字符串
im_data = ''.join(str(x) for x in list(im.getdata()))
这时候就会得到图片对应的字符串,将字符串与数据库进行比较,就可以了(当然这里的验证码分割后会更好处理)
完整的验证码识别代码
- 定义图片的一些基本信息(图片的一些基本信息,识别过程中也可以随时调整)
#验证码图片数量
imgNum = 100
#灰度阀值
threshold = 127
table = [0 if i < threshold else 1 for i in range(256)]
#图片信息
info = {
"offsetWidth": 2, #宽度偏移
"offsetHeight": 4, #高度偏移
"wordNum": 4, #字符数量
"wordWidth": 12, #字符宽度
"wordHeight": 12, #字符高度
"wordSpace": -2 #字符空隙
}
- 获取验证码图片
import requests
cookies = requests.get('http://www.domain.com').cookies
for i in range(imgNum):
img = requests.get('http://www.domain.com', cookies = cookies).content
with open('code/%s.jpg' % i, 'w') as f:
f.write(img)
- 验证码图片分割,分割为单个字符一个图片
import Image
for i in range(imgNum):
im = Image.open("code/%s.jpg" % i)
#分割单个字符
for j in range(info['wordNum']):
beginX = info['offsetWidth'] + (info['wordWidth'] + info['wordSpace']) * j
beginY = info['offsetHeight']
endX = beginX + info['wordWidth']
endY = beginY + info['wordHeight']
box = (beginX, beginY, endX, endY)
im.crop(box).save('part/%s-%s.jpg' % (i,j))
分割后部分图片效果
![]()
![]()
![]()
![]()
图片手动选择
- 这一步我处理的很蛋痛
- 这一步的目的就是用后面的代码生成数据库
- 操作方法:手动选择较好的图片并将图片

- 灰度处理后二值化,然后统计,生成字符数据库
import os
keys = {}
path = "part/"
folders = [x for x in os.listdir(path) if os.path.isdir(path + x)]
for key in folders:
imgFlag = []
tmpPath = path + key + '/'
files = [tmpPath + x for x in os.listdir(tmpPath) if os.path.isfile(tmpPath + x)]
for img in files:
im = Image.open(img).convert('L')
im = im.point(table, '1')
imgData = ''.join(str(x) for x in list(im.getdata()))
for i in range(len(imgData)):
if(len(imgFlag) <= i):
imgFlag.append([0,0])
imgFlag[i][int(imgData[i])] += 1
keys[key] = ''.join('0' if flag[0] > flag[1] else '1' for flag in imgFlag)
- 正常情况下,每个字符对应的值就存放在 keys 里面了,可以输出看看
import json
print json.dumps(keys, indent=2)
输出的结果如下:
{
"c": "111111111111111111111111111111111111111100001111111000000111110001101111110011111111110011111111110011111111110001111111111000001111111100011111",
"b": "111111111111110011111111110011111111110000001111110000000111110001100011110011110011110011110011110011110011110001100011110000000111111000001111",
"m": "111111111111111111111111111111111111111000001100110000000000110001000010110011100111110011100111110011100111110011100111110011100111111111111111",
"n": "111111111111111111111111111111111111111000000111110000000011110001100011110011110011110011110011110011110011110011110011110011110011111111111111",
"1": "111110111111111100011111111000011111111000011111111110011111111110011111111110011111111110011111111110011111111110011111111110011111111111111111",
"3": "111000001111110000000111111111000111111111000111111110001111111110001111111111000111111111100111110111100111100011000111110000001111111000011111",
"2": "111000011111110000001111100011000111110111100111111111100111111111001111111110001111111100011111111000111111110000111111100000001111110000001111",
"v": "111111111111111111111111111111111111111111111111110011100111110011100111111001001111111000001111111000001111111100011111111100011111111110111111",
"x": "111111111111111111111111111111111111111011101111110001000111111000001111111100011111111100011111111100011111111000001111110001000111111011101111",
"z": "111111111111111111111111111111111111111000001111111000000111111110001111111110001111111100011111111000111111111000111111110000001111111000001111"
}
现在数据库也有了,那么可以进入识别阶段了
- 验证码识别
import difflib
for i in range(imgNum):
codes = code = ""
im = Image.open("code/%s.bmp" % i).convert('L')
#分割单个字符
for j in range(info['wordNum']):
beginX = info['offsetWidth'] + (info['wordWidth'] + info['wordSpace']) * j
beginY = info['offsetHeight']
endX = beginX + info['wordWidth']
endY = beginY + info['wordHeight']
box = (beginX, beginY, endX, endY)
imgData = ''.join(['0' if x > threshold else '1' for x in list(im.crop(box).
getdata())])
percent = maxPercent=0.0
#选取相似度最大的值
for key in keys:
percent = difflib.SequenceMatcher(None, imgData,keys[key]).ratio()
if percent > maxPercent:
maxPercent = percent
code = key
codes += code
print i, codes